
База знаний в компании всегда была странной штукой. С одной стороны, без неё работают только малые команды до десяти человек — за пределами этого размера непереданная информация превращается в долг. С другой — почти ни в одной компании, где она «есть», ею реально пользуются. Wiki заводится, наполняется, ветшает, забывается. Confluence содержит сотни страниц, на которые никто не заходит. SharePoint становится свалкой PDF.
Это была хроническая проблема, к которой все привыкли. И вдруг за последние два года она стала острой. Не потому что Confluence стал хуже, а потому что у документов появился новый потребитель: ИИ-агенты, которые делают работу качественно настолько, насколько у них качественный контекст. И тут оказалось, что состояние корпоративной базы знаний — это уже не вопрос удобства сотрудников, а прямой ограничитель скорости компании.
Эта статья — про то, что в реальности происходит с корпоративными знаниями в 2026 году. Не «AI всё изменит», а именно: что ломается в старых подходах, какие архитектуры приходят на смену, где они в свою очередь ломаются, и как это будет выглядеть через 3–5 лет.
Почему классический wiki не работает (и не работал)
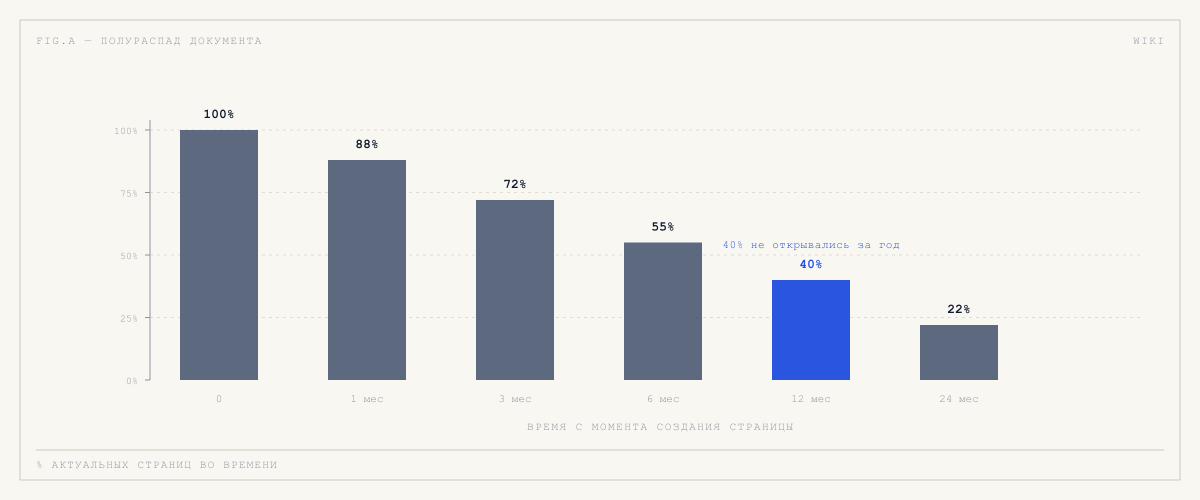
Полураспад документа
В любой работающей компании содержание документа стареет быстрее, чем сама компания об этом узнаёт. По полевым наблюдениям внутри средних и крупных IT-команд:
- около 40% всех страниц в корпоративной wiki не открывались за последний год;
- средний возраст последнего обновления у регулярно используемых страниц — порядка 11 месяцев;
- около 60% страниц, заведённых на онбординге новичка, перестают быть актуальными в течение полугода.
Это и есть «мёртвая wiki» — формально она есть, по факту её нет.
Поиск, который не находит
Полнотекстовый поиск в Confluence, Notion и SharePoint работает по принципу «ключевое слово в тексте» с улучшениями ранжирования. Когда коллекция вырастает за тысячу страниц, эта модель проигрывает: запрос «как настроить VPN для отдела X» возвращает 47 результатов, из которых 3 устаревшие, 2 черновика, и 1 актуальный — но он на четвёртой странице.
Решение «давайте все будем добавлять теги и метаданные» не работает. Тегирование требует дисциплины, которая возможна только в командах до 50 человек.
Tacit knowledge — то, чего там нет
Самая дорогая часть корпоративных знаний никогда не попадала в wiki в принципе. Как мы обычно отказываем клиенту-непрофилю, почему именно этот вендор лучше для нашего сетапа, где сидят грабли при интеграции с системой X — всё это живёт в головах людей и переходит через разговоры. Когда такой человек уходит, его опыт уходит вместе с ним.
Владение и амнистия знаний
Любая wiki без явного владельца страницы гнётся под весом неактуальной информации. А назначить владельца на каждый документ — это новая роль, которую никто не хочет.
Эти четыре проблемы существовали задолго до AI. Все четыре только что выросли в важности.
Цифры, которые объясняют, почему сейчас
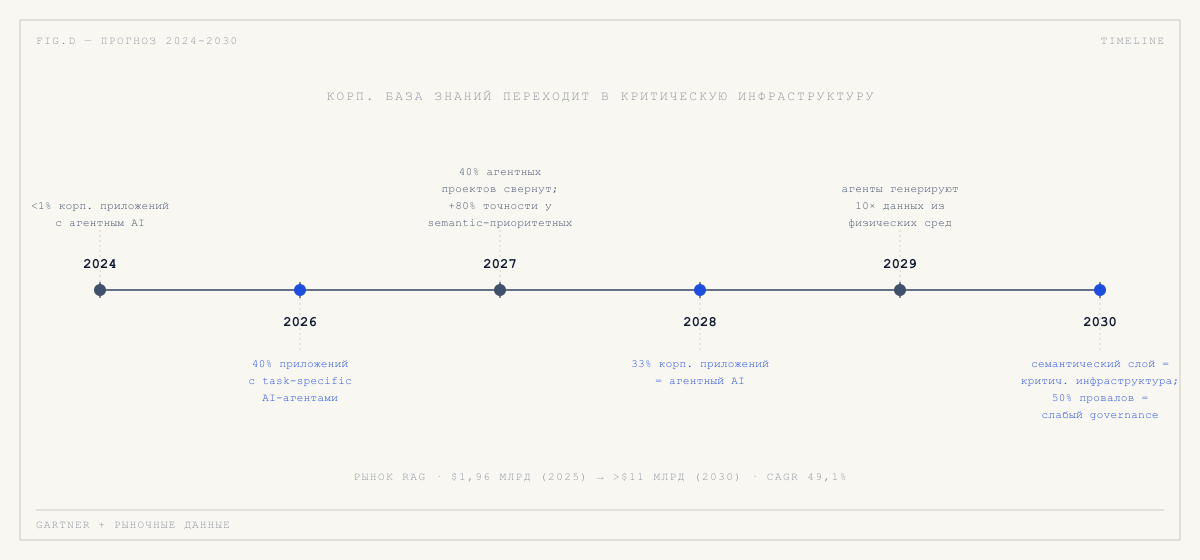
- Рынок RAG (retrieval-augmented generation) — $1,96 млрд в 2025 году, прогноз свыше $11 млрд к 2030 при среднегодовом росте 49,1%.
- 85% корпоративных AI-приложений в 2025 году уже используют RAG как ядро архитектуры (против 40% в 2023).
- 57% организаций оценивают свои данные как «не готовые для AI». Это значит, что почти у двух третей компаний внедрение RAG упрётся в первую очередь в данные, а не в модель.
- Только 4% организаций имеют по-настоящему интегрированную систему знаний; остальные работают на лоскутах.
- 82% предприятий регулярно срывают рабочие процессы из-за разрозненности данных (исследование IBM).
И главная цифра, которая ставит всё в перспективу: MIT NANDA Project зафиксировал, что 95% корпоративных AI-пилотов не дают измеримого эффекта на бизнес-результат. Когда смотришь, почему, в трёх из четырёх случаев ответ — состояние корпоративных знаний.
Архитектуры: RAG, GraphRAG, гибрид — без хайпа
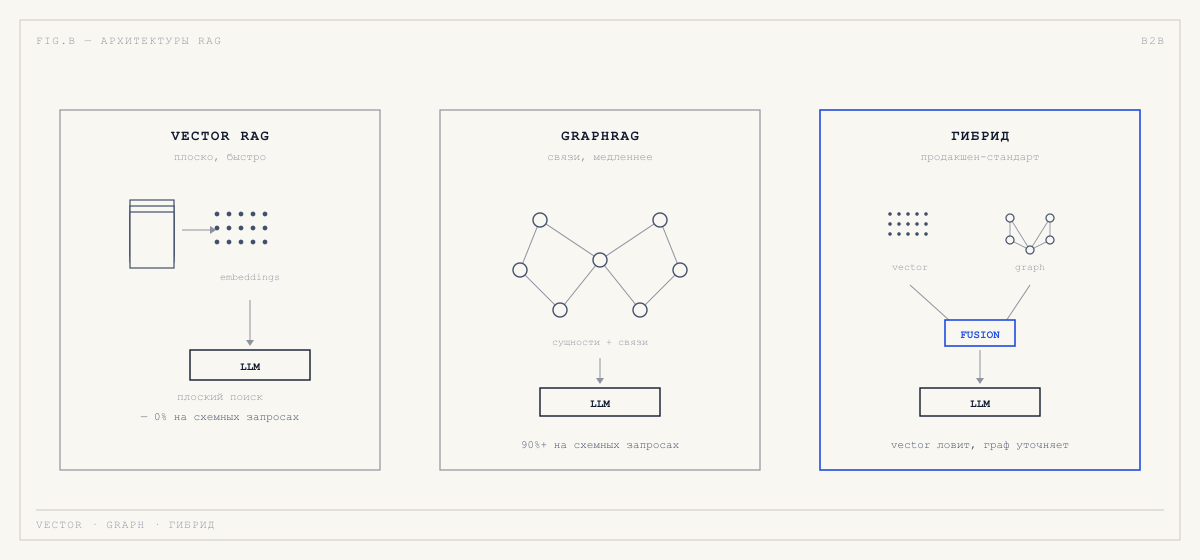
Vector RAG: то, на чём построено большинство пилотов
Базовая идея проста. Документы рубятся на куски (chunks), каждый кусок переводится в численное представление (embedding), всё это хранится в векторной БД (Pinecone, Weaviate, Qdrant, pgvector). На запрос пользователя — рубим запрос, ищем близкие куски, подкладываем как контекст в LLM. Это работает.
Это работает, пока запросы — фактологические и плоские. «Какие у нас сроки гарантии на продукт X» — отвечается отлично. «Покажи все случаи, когда мы продавали продукт X предприятиям пищевой промышленности с потребностью более 10 машин и сравни их с похожими по объёму контрактами в металлургии за последние три года» — ломается полностью, потому что:
- запрос требует обхода связей (продукт → клиент → отрасль → размер сделки → сравнение);
- одного chunk недостаточно — нужна агрегация по нескольким;
- семантика «больше 10 машин» — численное условие, плохо переводящееся в embedding.
По свежим бенчмаркам, vector-only RAG даёт 0% точности на запросах с такой структурой. Не «низкую» — нулевую.
GraphRAG: знание как граф
GraphRAG предлагает другую идею. Документ парсится сначала на сущности (компания, продукт, договор, отрасль) и связи между ними. Получается граф, на котором запросы выполняются как обход узлов и рёбер. На запросах, требующих обхода связей, GraphRAG достигает 90%+ точности там, где vector RAG даёт ноль.
Цена: построение графа дороже на порядок. Нужны качественные данные, схемы, экстракция сущностей. И на простых фактологических запросах GraphRAG не быстрее vector RAG — а часто медленнее.
Гибрид как реальный продакшен
В 2025–2026 годах в реальных корпоративных внедрениях побеждает гибрид: vector retrieval для предварительного поиска кандидатов, граф для уточнения и проверки результатов. Vector ловит «о чём вообще речь», граф отвечает на «как это связано с остальным». Это сейчас де-факто стандарт серьёзных корпоративных внедрений.
Маркетинг говорит, что GraphRAG даёт прирост точности 30–50%. Контролируемые мета-анализы 2025 года показывают, что на типичной смеси запросов прирост ближе к 5–10%. Но на критически важных сложных запросах разница может быть 0 vs 90+. Каждое внедрение должно решать само, какие именно запросы для него критичны.
Почему наивный RAG ломается на проде
Когда смотришь, что именно ломается в 95% пилотов, выходит интересная картина:
- 73% провалов RAG — это не модель, а плохие стратегии чанкования (chunking). Слишком большие куски — модель тонет в шуме. Слишком маленькие — теряется контекст.
- Галлюцинации — модель уверенно генерирует факты, которых нет в источниках. Решается reranking + source attribution + явная инструкция «если не уверен — скажи».
- Stale знания — RAG ищет в индексе, который не пересобирается. Через две недели он отвечает по устаревшим документам.
- Отсутствие governance — кто видит какие документы. По прогнозу Gartner, к 2030 году 50% провалов агентных AI-систем будут связаны именно с этим.
Эти провалы не про AI как таковой. Это про инженерную дисциплину, которой в большинстве пилотов нет.
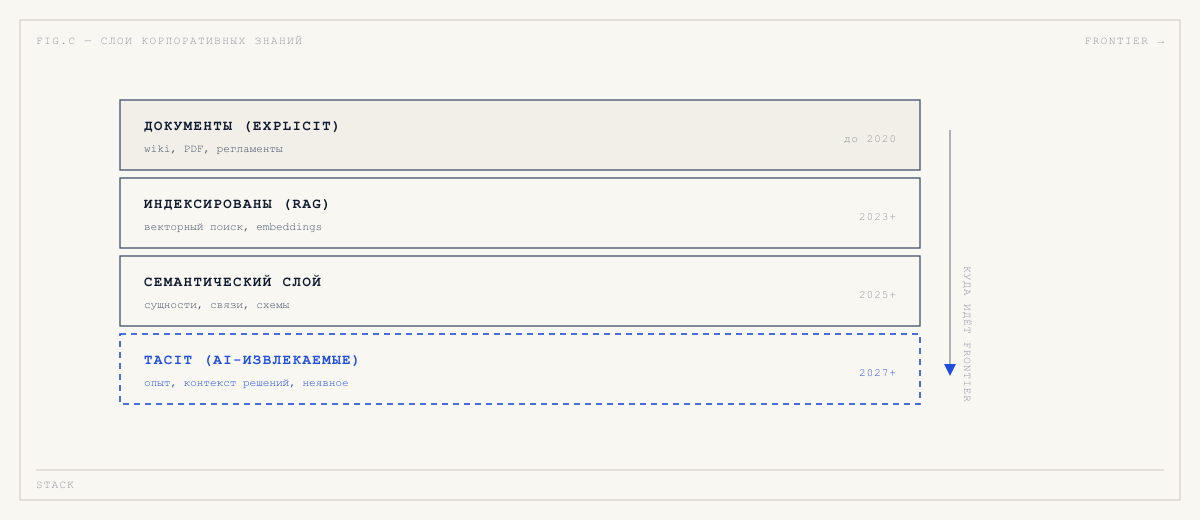
Семантический слой как новая критическая инфраструктура
Здесь сходится самый интересный тренд. Gartner прогнозирует:
К 2030 году универсальный семантический слой будет рассматриваться как критическая инфраструктура — наравне с платформами данных и кибербезопасностью.
Что это значит на практике. Семантический слой — это явная схема того, что в компании понимается под основными сущностями: что считать «клиентом», что считать «контрактом», как связаны «продукт» и «услуга», какие у них статусы и переходы. Раньше эта схема жила в головах ключевых сотрудников. Теперь её придётся явно описать — потому что иначе AI-агенты не смогут с ней работать.
И вот цифра, которая показывает, насколько это серьёзно: к 2027 году компании, которые приоритизируют семантику в AI-ready данных, увеличат точность GenAI-моделей до +80% и снизят стоимость до −60%.
Дело не в моделях. Дело в том, что одна и та же модель на одних и тех же документах даёт совершенно разный результат, если ей даны или не даны явные семантические правила.
ИИ-агенты как новый потребитель знаний
Долго база знаний была про людей, которые её читают. Теперь главный потребитель — это агент, который её использует. Это меняет требования:
- Документ для человека: иерархия глав, оглавление, длинные параграфы.
- Документ для агента: атомарные факты, явные источники, машинно-читаемые связи.
Это две очень разные задачи. И большинство компаний пока решают первую, в то время как с 2026 года давление приходит со второй.
Конкретный пример. Когда инженер пишет в Claude Code или Cursor «настрой деплой по образцу того, что мы делали для проекта X», LLM не может понять «образец проекта X» иначе, чем через явный контекст. Если в компании есть CLAUDE.md или AGENTS.md для X, агент сможет. Если нет — придётся объяснять всё руками. Это и есть организационная амнезия: знание не накапливается на уровне компании, а перетекает между конкретными людьми.
Сейчас активно растёт новый класс инструментов: GBrain (Y Combinator), OpenBrain, Mem0, Zep, Letta, LangMem — все они занимаются одной задачей: централизованный слой памяти, доступный всем AI-инструментам компании. Через 2–3 года это станет такой же базой, как сейчас GitHub или Slack.
Tacit knowledge: то, что не попадает в документы
Самое интересное обещание агентных систем — извлечение tacit knowledge автоматически, без явного документирования. Сценарий: агент работает рядом с инженером, видит, какие решения принимаются и почему, и сам инкорпорирует их в общую базу.
По прогнозу Gartner, к 2027 году разрыв «цена–ценность» процессно-ориентированных сервисных контрактов сократится минимум на 50% — именно за счёт того, что AI-агенты начнут открывать tacit knowledge.
Это сильное обещание. Но осторожно: 2027 — это ровно тот же год, когда Gartner также прогнозирует, что 40% агентных AI-проектов будут свёрнуты. Технология обещает, технология споткнётся на масштабе, технология вырастет дальше. Стандартная кривая хайпа.
Где это всё ломается на самом деле
Технические провалы — это меньшая часть. Большая часть — организационная:
- Резистенция к документированию. Никто не хочет тратить время на «не свою» работу. Любая система знаний, требующая дисциплины от каждого сотрудника, провалится. Системы, в которых документирование происходит как побочный эффект работы (commits, чаты, тикеты), выживают.
- Конфликт владения. Когда два отдела не согласны, какой документ считается «истиной», система знаний без явного процесса разрешения противоречий зависает.
- ROI, который не измеряется. Внедрение RAG-системы на 50 человек стоит несколько миллионов рублей. Без явной метрики «что мы получили» проект через год превращается в «зачем мы это вообще делали».
- Интеграционная сложность. Корпоративные данные раскиданы: CRM, ERP, почта, тикет-системы, личные документы. Подключение каждого источника — это отдельный проект.
Прогноз 2026–2030
Соберём то, что прогнозируют ведущие аналитики, и то, что видно в трендах.
К 2026 году: 40% корпоративных приложений будут иметь встроенных task-specific AI-агентов (Gartner). Это значит, что состояние корпоративных знаний станет фактором, видимым не только IT-отделу, а и продажам, HR, поддержке.
К 2027 году: 40% агентных AI-проектов будут свёрнуты — на чистке после хайпа (Gartner). Выживут те, у кого изначально была инженерная дисциплина и явный семантический слой.
К 2028 году: 33% корпоративных приложений будут включать агентный AI (с менее 1% в 2024). Это переход от «новой технологии» к «новой норме».
К 2029 году: AI-агенты будут генерировать в 10 раз больше данных из физических сред, чем все цифровые AI-приложения вместе. Это значит, что база знаний компании будет в значительной части собираться автоматически — из IoT, сенсоров, видео, действий агентов.
К 2030 году: Универсальный семантический слой станет критической инфраструктурой наравне с дата-платформами и кибербезопасностью (Gartner). 50% провалов агентных систем будут связаны с недостаточным governance.
В сумме это означает: за следующие пять лет корпоративная база знаний переходит из категории «нужно, но необязательно» в категорию «без этого не работает агентная AI». А агентная AI — это то, на что компании уже сейчас закладывают огромные бюджеты.
С чего разумно начинать
Если вы заводите этот проект сейчас, четыре совета.
-
Не начинайте с инструмента. Начните с двух-трёх кросс-функциональных вопросов, на которые в компании сложно быстро получить ответ. Если ваша система не отвечает на них через 6 месяцев — она не работает.
-
Семантический слой раньше векторов. Дешевле сначала договориться о схеме (что такое клиент, контракт, продукт), потом строить retrieval, чем наоборот. Откатить семантику дороже, чем переиндексировать векторы.
-
Документирование как побочный эффект работы. Не пытайтесь заставить людей писать дополнительно. Стройте на том, что уже пишется: commits, тикеты, переписка, заметки встреч. AI-агенты должны извлекать, а не требовать.
-
Измеряйте, сколько раз агент сказал «не знаю». Хорошая метрика — не «сколько документов в базе», а «сколько раз агент сказал не знаю». Если эта метрика падает — значит, база растёт правильно. Если стоит — стоит и работа.
Коротко
Корпоративная база знаний перестала быть вопросом удобства сотрудников. Она становится инфраструктурой, на которой работают AI-агенты, и состояние этой инфраструктуры определяет, какие задачи компания может автоматизировать, а какие — нет. Архитектуры — vector RAG, GraphRAG, их гибрид — это инструменты, а не самоцель. Главное — иметь явный семантический слой, инженерную дисциплину работы с данными и метрику, по которой видно, окупается ли всё это.
Через пять лет это будет такой же базой, как сейчас система контроля версий или Slack: «без этого компания не работает». Сейчас мы только в начале этого перехода, и большая часть пилотов проваливается. Это нормальная стадия. Важно не пропустить момент, когда пилоты, прошедшие через эту стадию правильно, начнут отрываться от тех, кто не прошёл.
Если у вас есть запрос на внедрение базы знаний под AI-агентов — напишите, обсудим. На нашей стороне это пересекается с услугой AI-автоматизации: мы помогаем выстроить семантический слой и retrieval-инфраструктуру вокруг данных, которые у вас уже есть.